这是在北邮 GAMMA LAB 实习期间精读的一篇 paper,原文链接为 HHGN: A Hierarchical Reasoning-based Heterogeneous Graph Neural
Network for fact verification
一、前置知识
- Token:通常指的是文本中的一个单元,例如一个单词、字符或子词。例如,句子 “I love apples.” 可以被分解成词语 tokens:[“I”, “love”, “apples”, “.”]。
- “text span” 是指文本中的一个连续片段,通常由一系列相邻的词语或字符组
成。在自然语言处理中,文本片段可以是一个单词、一个短语、一个句子,
甚至是一个更长的片段,取决于具体的上下文和任务。
二、概念引入
在互联网信息爆炸的今天,我们需要一种工具,能够自动地检验互联网上的
信息真实与否。这种技术叫做“事实验证”(Fact Verification)
事实验证中,输入信息称为“主张”(Claim),这是一个待验证的论断或主张,
通常是一个陈述性句子,需要经过验证以确定其真实性或准确性。算法要求
根据主张的信息,通过 Wikipedia 等权威平台进行检索从而获取 “证据”
(Evidence)。
证据是一个或多个句子,提供了支持或反驳这个主张的信息,通常是与主张相关的背景信息、数据、事实等。事实验证需要根据检索到的“证据句”(Evidence Sentence),从三个 Label 中选择其一对主张进行评价。它们分别是:
- SUPPORT
- REFUTE
- NOT ENOUGH INFO
例如下面的主张 Home for the Holidays stars an American actress

我们希望能设计一个系统,提取出 Home for the Holidays 和 American actress 两个关键词,并且在语料库中查找这两个 Evidence 所对应的事实,从而验证原本的主张是否正确。在此例中,语料库指出 Home for the Holidays 这部电影的主角是 Holly Hunter,而 Holly Hunter 在语料库中也提到她是一个美国演员,因此原主张成立。
以往的事实验证通常基于 Natural Language Inference(NLI)来实现。
NLI 是自然语言处理领域中的一个任务,其目标是判断给定两个句子之间的
逻辑关系,通常包括三种情况:蕴涵(entailment)、中性(neutral)和矛盾
(contradiction)。这个任务的核心在于理解一句话是否可以从另一句话中推
断出来。
在事实验证中,通过将主张和相关证据组成句子对,然后使用 NLI 技术来判
断主张和证据之间的逻辑关系,可以帮助确定主张是否在给定的证据下是真
实的或可信的。这个过程可以通过 NLI 模型来执行,模型会根据主张和证据
之间的语义和逻辑关系,判断主张是否与证据一致(蕴涵关系)或矛盾(矛
盾关系)。
但这种方法忽视了不同的证据句之间的语义联系。对于需要多个不同的证据
句才能验证的主张,这种方法就难以处理。
为了解决这一问题,自然而然想到用节点来表示一个个证据句,然后将证据
句连接成图,从而实现各个证据句之间的信息流通。但这样的方法仍然存在
如下的不足:
- 只能提取“语句尺度”(Sentence-level)的特征,而忽视了“实体尺度”
(Entity-level)和“上下文尺度” (Context-level) - 缺乏对于事实验证的可解释性(interpretability)
- 现有模型通常单独关注于特定情景下的事实验证,即单一证据或多个证据,
这在两种情景下都不能很好地发挥作用。
为了提供多种不同尺度下的语义信息,并且提供可解释性,作者提出了基于
分层推理的异构图神经网络,Hierarchical Reasoning-based Heterogeneous
Graph Neural Network(HHGN)。原来的图中只有证据句一种节点,现在引
入了实体节点和上下文节点,构成了异质图来表示三种不同节点之间的语义
关系。
作者表示,这样基于分层推理来从不同尺度对主张进行论断,可以有效提升
模型的精确性。
三、网络结构
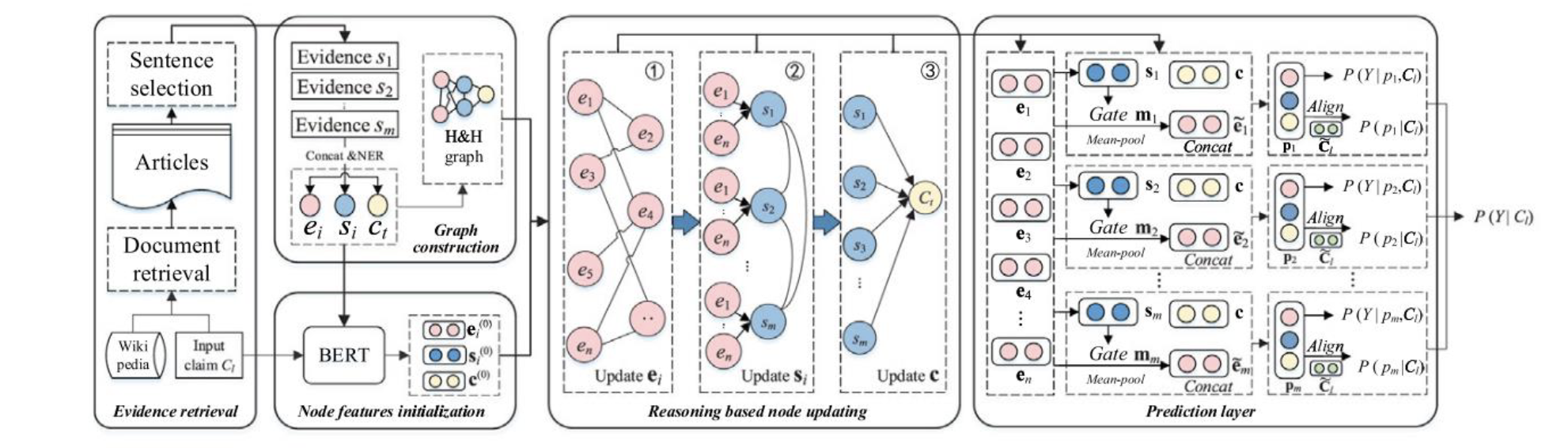
本文中提到的工作流程可分为五个部分
- 证据检索(Evidence retrieve)
- 图构建(Graph construction)
- 节点特征初始化(Node feature initialization)
- 基于推理的节点更新(Reasoning Based Node Updating)
- 预测层(Prediction Layer)
用图像表示为
1. 证据检索
对于证据检索这部分的要求,我们会输入主张 $C_l$ 以及大量的来自 Wikipedia 的权威文章,从而生成与主张相关的证据序列。具体实现步骤如下:
- 对于每个主张,首先采用 Constituency Parser Toolkit 提取出与主张可能相关的实体(Entity)。这里的实体并非只是名词,还包括主要动词和主张本身。
- 然后调用 MediaWiki API 在 Wikipedia 中搜索相关程度最高的 𝑘 篇文章,表示为
$A=\{A_1,A_2,\cdots, A_n\}$ 。在得到文章之后,我们需要从文章中提取关键的句子作为证据句。给定一个主张和对应的一篇文章,采用一种基于 BERT 的检索模型,以损失函数的方式来对文章中的句子进行打分,具体规则为
$$L_{Re}=\sum \max(0, 1+Score_n-Scorn_p)$$
评分之后,我们就得到了证据序列 $S=\{s_1,s_2,\cdots, s_m\}$
2. 图构建
图构建部分接收来自上一环节的证据序列 $S$ 作为输入,并构建一个由证据组
成的图。为了能够从不同尺度验证主张,图是由三个不同尺度的证据的节点
所组成的异质图,从微观到宏观分别是“实体尺度” (Entity-level), “语句
尺度”(Sentence-level)和“上下文尺度” (Context-level)。如下图
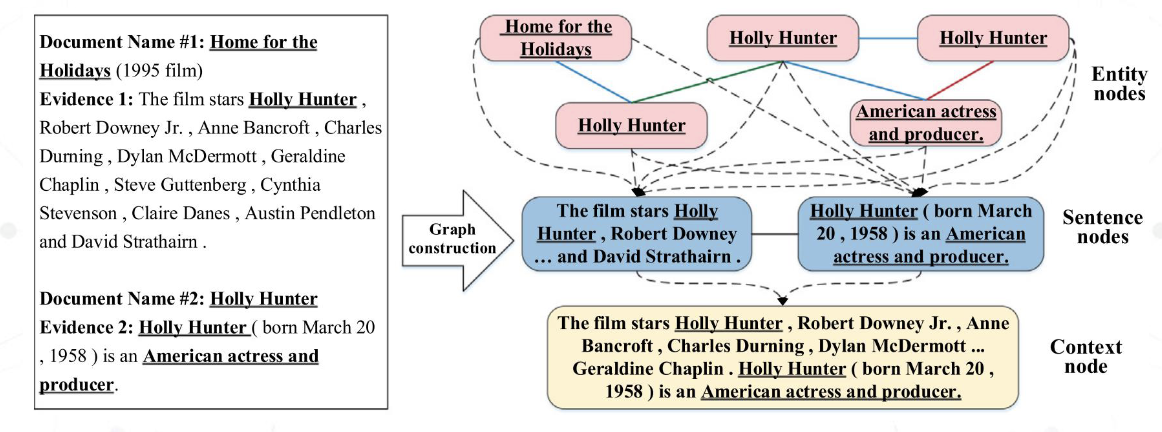
首先对于证据序列 $S$,我们将其中所有句子拼接起来,称为序列文本
(Sequential text),记为 $C_t$,将其作为上下文节点。而证据序列 $S$ 中的每
句话就是语句节点。再使用 NER(一种自然语言处理工具)将所有证据据中
的名词短语提取出来,作为实体节点,记为 $e_i$ 。注意,同一个名词可能对应
多个同名节点。
在边构建方面,我们在每个微观节点到宏观节点之间都连接一条有向边来实
现信息从底层到上层的传输,其次,同一尺度的节点之间以无向边相连,实
现同尺度的信息沟通。
为了彻底提取实体间的关系,并且抑制无关节点带来的噪声,可以将实体尺
度节点之间的无向边分为三类:“Sentence-level Edge”(语句尺度边),
Context-level Edge (上下文尺度边) 和 Article-level Edge (文章尺度边)
- “Sentence-level Edge”(语句尺度边)指的是在同一句话中,不同实体间的关
系。 - Context-level Edge (上下文尺度边) 指的是不同文章中,同一实体间的关系。
- Article-level Edge (文章尺度边) 指的是在某一篇文章的标题中出现了的实
体所代表的节点,称为中心节点(Central node),与文章剩余部分出现的节
点之间的关系。
以上,我们得到了一个由不同尺度的证据节点所组成的异质图。这也就对应
了这篇 paper 的标题:HHGN: A Hierarchical Reasoning-based
Heterogeneous Graph Neural Network for fact verification
3. 节点特征初始化
节点特征初始化这一部分,我们接收主张 $C_l$ 以及证据序列 $S$,需要对上文我
们构建出的异质图中的节点进行初始化。 我们首先将主张 $C_l$ 与序列文本 $C_t$
拼接在一起并进行 BERT 编码得到此主张和证据的标记(Token),这是一个
长度为 $d_1$ 的一维张量,记为 $c^{(0)}$
$$c^{(0)}=BERT([C_l,C_t])$$
其中 $d_1$ 指的是 BERT 中间表示向量的大小。然后我们应用一个双注意力层
(Bi-Attention layer) 来增强主张和证据的交互性,得到了一系列的 Token,
对于主张,Token 序列为 $C_l=[c_1^l,\cdots c_{L_1}^l]\in R^{L_1\times d_1}$,对于证据,Token 序列为 $C_t=[c_1^t,\cdots ,c_{L_1}^t]\in R^{L_2\times d_1}$。其中,$L_1,L_2$ 分别代表了主张和证据的 Token 数
得到 Token 序列以后,我们需要进一步得到能够帮助我们分析主张的文本片段
(Text Span),并且由此来创建实体节点的表征。具体来说,我们创建一个二元
矩阵 M 来记录关于文本片段的信息。若证据中的第 𝑗 个 token 处在第 𝑖 个 token
的文本片段范围内,则 𝑀𝑖𝑗 = 1,否则 𝑀𝑖𝑗 = 0
然后将矩阵 $C_t$ 和二元矩阵 $M$ 做矩阵乘法,我们就可以得到 $𝐶_t$ 的实体相关行。
最后,我们引用一层平均池化层和最大池化层来分别将这些融合。这些文本片段
在进行拼接,并且送入一个 MLP 层来得到最终的实体节点表示 $e_i^{(0)}\in R^{d_1\times 1}$。对于 $n$ 个实体,就是一个矩阵 $E^{(0)}=[e_1^{(0)},\cdots e_{n}^{(0)}]\in R^{d_1\times n}$
对于语句节点,我们将主张和每个证据句拼接在一起,同样也送入 BERT 来得到语
句节点的特征表示 $s_i=R^{d_1\times 1}$,以及对应的 $m$ 个证据句合在一起的矩阵
$$S^0=[s_1^{(0)},\cdots, s_m^{(0)}]\in R^{d_1\times m}$$
4. 基于推理的节点更新
在此部分中,我们通过基于推理的节点更新来为下游的预测工作提供新的节
点信息。比如为了建模人类的推理过程,我们限制了从细粒度节点到粗粒度
节点的消息传递。此外,我们还对同类节点更新和不同类节点更新应用了不
一样的更新算法。
为了彻底探索同类节点之间的语义关系,我们在实体节点之间以及语句节点
之间采用了图注意力机制。具体来说,给出 $t-1$ 层的节点信息 $E^{t-1}=[e_1^{(t-1)},\cdots, e_n^{(t-1)}]$,首先计算每对连接的实体的注意力分数 $\alpha$
$$\alpha_{i,j}^{(t)}=\frac{\exp(\beta_{ij}^{(t)}}{\sum_k\exp(\beta_{i,k}^{(i)}}$$
$$\beta_{i,j}^{(t)}=LeakyReLU(W_t^T|h_i^{(t)},h_j^{(t)}])$$
$$h_i^{(t)}=U_te^{t-1}_i+b_t$$
在这里我们选用 LeakyReLU 作为激活函数,$U_t\in R^{d_1\times d_1},b_t\in R^{d_1\times 1},W_t\in R^{2d_1}$ 是网络中可用训练的参数。这里的注意力分数 $\alpha_{i,j}$ 衡量了从实体 $i$ 到实体 $j$ 的特征传播的比例。然后我们通过累加邻居节点来得到节点的新信息,即
$$e_j^{(t)}=ReLU(\sum_{i\in B_j}\alpha_{i,j}^{(t)}e_i^{(t)})$$
其中 ReLU 就是我们选取的激活函数,$B_j$ 表示的是实体 $j$ 周围的邻居节点。由此,我们就可以得到更新过了的节点表示 $E^t=[e_1^{(t)},\cdots, e_n^{(t)}$。同理我们也可以得到语句节点的更新 $S^t=[s_1^t,\cdots, s_m^t]$
对于异类节点之间的更新,我们主要考虑两种类型。一是实体节点到语句结
点的更新,二是语句节点到上下文节点的更新。由于它们更新的方式大同小
异,因此我们以前一种,即实体节点到语句节点的更新为例展开分析。
不同于同类节点的更新策略,为了减少上游细粒度带来的影响,以及深度神
经网络中常见的过拟合问题,我们引入了门机制来控制向下游信息更新的比
例。比如给出 $t-1$ 层的实体节点 $E^{(t-1)}=[e_1^{(t-1)},\cdots, e_n^{(t-1)}]$ 以及语句节点 $S^{(t-1)}=[S_1^{(t-1)},\cdots, S_m^{(t-1)}]$,我们首先计算语句节点 $i$ 和实体节点 $j$ 之间的注意力分数。然后我们对于语句 $i$ 累加实体节点特征,记为 $z_i^{(t-1)}$
为了保持来自邻接节点的特征,我们将实体节点之和 $z_i^{(t-1)}$ 与语句特征 $s_i^{(t-1)}$ 结合起来,然后产出一个“候选语句节点” (Candidate Sentence Node),这是一个长度为 $d_1$ 的一维张量,记为 $u_i^{(t-1)}$,具体表示为
$$u_i^{(t-1)}=W_s(s_i^{(t-1)})+z_i^{(t-1)}$$
- 其中 $W_s\in R^{d_1\times d_1}$ 为一层 MLP 中的可训练参数。
- 由于图神经网络很容易导致过拟合问题,尤其是在层数很多的时候,因此我
们采用门机制来更新语句表示。具体来说,我们首先计算“相关分数”
(Relevance Score)$g_i^{(t-1)}$ 来权衡有多少比例的信息来自自身,而有多少比例信息来自之前提到的候选节点。
然后我们用此来生成更新的第 $t$ 层语句节点表示,用公式表示为:
$$g_i^{(t-1)}=sigmoid(W_g([u_i^{(t-1)};s_i^{(t-1)}]))$$
其中 sigmoid 和 tanh 为激活函数。$W_g\in R^{2d_1}$ 为 MLP 中的可训练参数,而 ⊙ 表示按元素乘法。以上是实体节点到语句节点的更新过程,对于语句节点到
上下文节点,也用到了类似的特征传播策略。
最后,为了对人类推理过程进行建模,我们按照如下步骤进行信息传播:
- 基于实体节点子图,对实体节点表示进行更新
- 通过聚合实体节点的信息来更新语句节点,再基于语句节点子图再次更新语
句节点 - 通过聚合语句节点的信息来更新上下文节
5. 预测层
这部分我们以更新过了的节点表示作为输入,然后返回对于事实验证的标签。
我们将会从多种不同的推理路径来进行预测,然后通过适当的加权得到最终
的结果。
我们认为推理是从细粒度到粗粒度的,即实体→语句→上下文。首先从实体
到语句这一过程,我们需要“辨识”(Discriminate)这些节点。首先计算这些
实体到语句 𝑖 的“相关度分数矩阵”(Relevance Scores Matrix)
$$m_i=[m_{i,1},\cdots ,m_{i,n}]=\sigma([\gamma_{i,1},\cdots, \gamma_{i,n}])$$
其中 $W_g\in R^{d_1\times d_1}$ 为权重矩阵,$\sigma$ 为 sigmoid 激活函数。
然后我们对这些被相关系数矩阵 $m_i$ 加权过的实体特征应用平均池化,得到
最终聚合的实体特征(the Final Aggregated Entity Representation),记为 $\tilde{e_i}$。这是一个长度为 $d_1$ 的一维张量,可以表示为
$$\tilde{e}_i=F_{mean-pool}(E_i)$$
$$E_i=F_w(m_i,E)=[m_{i,1},e_1,\cdots, m_{i,n}]$$
我们此时可以将语句节点和上下文节点的特征与 $\tilde{e}_i$ 拼接起来送入 MLP 的输入。在此之后,我们可以得到一条推理路径的最终表示,记为 $p_i$,这也是个一
个长度为 $d_1$ 的一维张量,可以表示为
$$p_i=W_p([\tilde{e}_i,s_i,c])$$
其中 $W_p\in R^{d_1\times 3d_1}$ 是一个可训练的神经网络。
在此之后,我们可以计算每条推理路径 $p_i$ 的“对齐向量”(Aligned Vector),用
$a_i$ 表示。
$$a_i=F_{align}(p_i,\tilde{C_l^T})$$
$$\tilde{C}_l=F_{mean-pool}(C_l)$$
$$F_{align}(x,y)=W_a[x,y,x-y,x\odot y]$$
其中 $\tilde C_l\in R^{d_1}$ 是主张里 Token 特征的平均池化结果,且 $F_{align}$ 表示了对输入 $x,y$ 进行对齐的函数。
接下来,我们可以通过上面得到的对其向量 $a_i$,生成给定主张时,选择推理路径 $p_i$ 的概率
$$p(p_i|C_l)=\frac{\exp(\theta_{p_i})}{\sum_{k=1}\exp(\theta_{p_k})}$$
其中 $W_1’\in R^{1\times H}$ 和 $W_0’\in R^{H\times 2d_1}$,这里的 $H$ 指的是隐藏层大小。
最终,我们可以对主张提出标签预测:
$$P(Y|C_l)=\sum_{k=1}^mP(Y|p_i,C_l)P(p_i|C_l)$$
其中 $Y$ 表示不同的标签,$P(Y|p_c,C_l)$ 指的是通过推理路径 $p_i$,对于给定主张的标签预测概率分布,可以表示为
$$P(Y|p_i,C_l)=softmax(W_lp_i)$$
其中 $W_l\in R^{3\times d_1}$ 是可训练参数。最终,训练模型方面,我们希望最小化交叉熵:
$$L=CrossEntropy(Q(Y),P(Y|C_l))$$
其中 $Q(Y)$ 表示“事实”的标签分布。
四、实验性能
FEVER 是一个经典的事实验证数据集,它包含了 18 万个标有“正确”
(SUPPORTED),“错误”(REFUTE)和“无法确定”(NOT ENOUGH INFO)
标签的主张。作者在 FEVER 数据集上做了测试,并且采用了标签准确性和
FEVER 分数两种评价标准来衡量模型的性能。其中,标签准确性只评价标签的
正确与否,而 FEVER 分数还要求模型是检索到的证据同样是正确的。
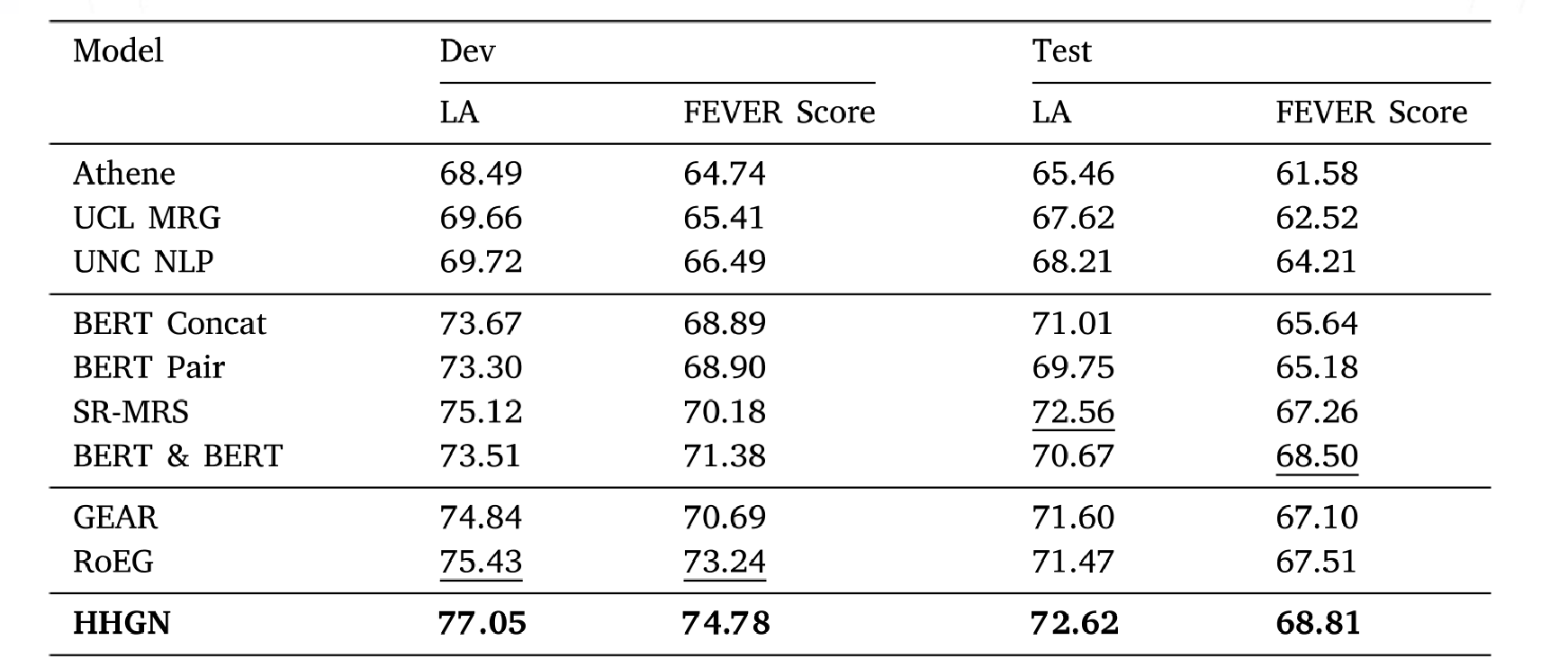
作者采用 FEVER 测试的结果如下图

作者团队为了进一步探究模型的效果,提出了如下问题
- 相比其他竞争对手,团队提出的事实验证方法是否具有明显的优越性?
- HHGN 在处理单证据样本和多证据样本的过程是否存在差异性?
- 节点数和边数是否会影响性能?
- 基于推理的节点更新和预测层是否真的提升了模型性能?
对于问题一,相比其他竞争对手,团队提出的事实验证方法是否具有明显的优越性?作者实验结果如下,可见优越性是显著的
对于问题二,HHGN 在处理单证据样本和多证据样本的过程是否存在差异性?
为了进一步探索模型的表现,作者根据验证主张(NOT ENOUGH INFO 的不
算在内)所需的证据数,将原始数据集分为两个子集,分别为单证据样本
(Single-Evidence)和多证据样本(Multi-Evidence)。分别作了相应实验后得
到的结果为
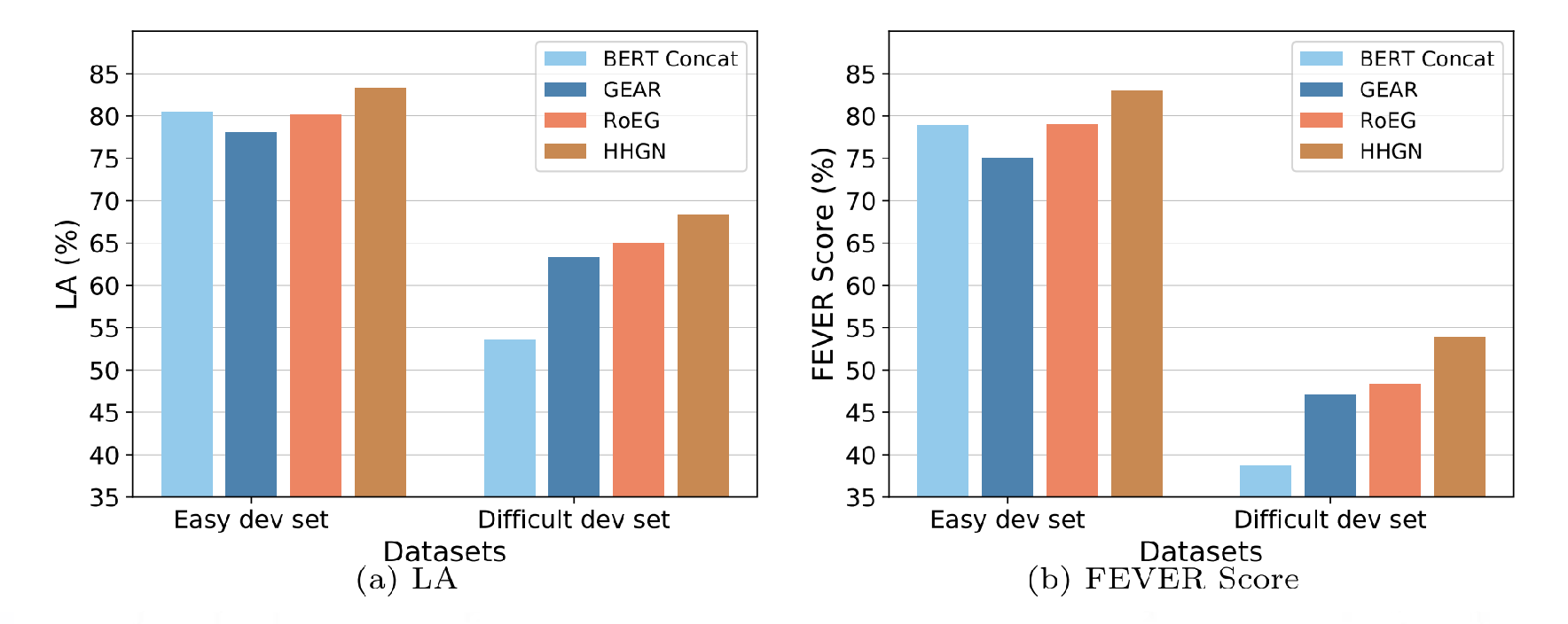
可以看到在标签准确度(LA)方面,HHGN 在简单集和复杂集都表现出了优
异的性能。而在难度方面,可以发现复杂集的 LA 在整体上是偏低的,这说明
需要多个证据来验证的主张在事实验证时的难度较高。
而在 FEVER 分数方面,简单集和复杂集的差距被进一步拉大,也就是说
FEVER 分数对主张复杂度会更加敏感。但可以看出,HHGN 此时仍然在所有模
型中表现最好。作者认为这是因为 HHGN 不仅能够给出主张的正确标签,更因
为它能够选择最优的推理路径。
对于问题三,节点数和边数是否会影响性能?为了检验构建的图中的节点数带来的影响,作者根据节点数划分了八个不同的子集,根据边数划分了九个不同的子集分别进行测试。得到结果如下图
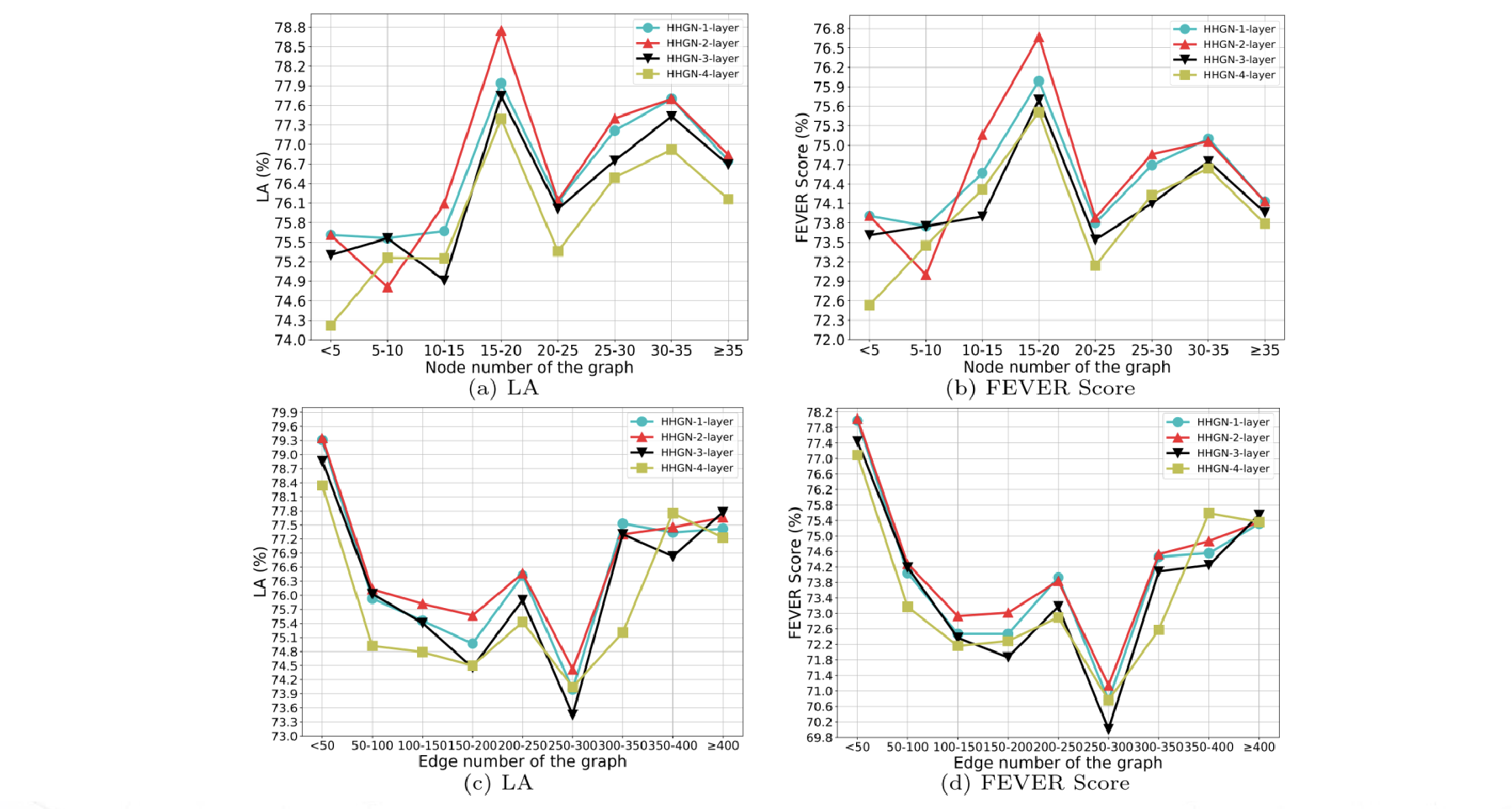
首先是层数选择方面,可以看到使用两层 HHGN (红色折线)的性能是最好
的,这说明层数并不是越多越好。一定量的推理层数就足以实现推理所需要的
信息交换。如果层数过多,可能会发生过拟合现象,从而导致语义信息丢失。
然后是节点数方面,可以看到整体上来说模型的性能随着节点数的增加呈现
先增后减的趋势,这表示节点数越多,模型越能捕捉到证据中的关键信息,但
同时也会引入一些与推理无关的噪声信息导致性能下降。
最后是边数方面,与节点数的趋势相反,可以看到整体上来说模型的性能随
着边数的增加呈现先减后增的趋势。作者认为,随着边数增加,图结构的复杂
度升高,这不可避免地引入无关节点之间的信息交换。但边数达到一个比较大
的量级时,模型就可以提取出一些高度相关的实体作为证据,使得引入的噪音
被抑制。
对于问题四,基于推理的节点更新和预测层是否真的提升了模型性能?为了检验节点更新和预测层这些操作的有效性,作者分别去掉了这两个关键
环节,再次进行了实验,得到的结果如图

可以看到,无论去掉哪个部分,都会使得性能产生大幅度下降。这说明了这
两个环节在提高模型准确性上都有重要的意义
五、结论
在本篇论文中,我们引入了一种基于分级推理的异质图神经网络
(Hierarchical reasoning-based Graph Neural Network,HHGN)来解决实施验
证方面的问题。HHGN 采用一种特别的图注意力网络来捕捉不同语义单元之间
的关系。为了对人类的推理过程进行建模,HHGN 应用了分层结构来传递特征。
此外,考虑到一些情况需要单个或多个证据句来验证主张,HHGN 可以通过不
同的推理路径来做出推断。实验结果表明,HHGN 方法比起数据集上的其他竞
争对手具有性能上的优越性,也就是说,HHGN 能够提供一种可解释的,语义
学上的方式来有效验证主张。
发表回复