1. 介绍
交通标志识别(Traffic-sign recognition, TSR)是一种通过计算机视觉和机器学习技术,使车辆能够自动识别和理解道路上的各种交通标志的技术。例如,车辆能够识别“限速”、“儿童过街”或“前方转弯”等标志,并做出相应的反应。这项技术在自动驾驶汽车中至关重要,因为它帮助车辆在复杂的道路环境中安全、有效地导航,并遵守交通法规。
然而,成功的 TSR 系统仍面临一些障碍,因为其性能显著受到影响道路标志可见性的环境因素的影响。道路标志由于照明问题和恶劣天气可能暂时不太明显,或因破坏和不合适的标志设置永久性地不太明显。
在本研究中,提出了一种多特征融合分类方法,以准确消除照明因素的问题,从而准确估计形状并识别不同形状的含义。基于颜色直方图,HOG 特征描述符,内外分别识别的 GIST 特征描述符,结合使用交通标志训练的卷积神经网络(CNN),从多方面提取出交通标识的特征,从而更好的进行分类。
2. 数据预处理
考虑到输入数据中的图像尺寸,曝光度差别较大,因此在特征提取之前,首先进行 ROI 提取,找出交通标识的最大外接矩形,然后将其缩放到 48×48 的尺寸,最后对 RGB 三个颜色通道进行直方图均衡,得到预处理后的图像。
3. 特征提取
在本次研究中,提出了一种集成了多种描述方式的特征提取方法。我们认为,交通标识信息包含了颜色信息,形状/纹理信息和符号信息。针对这三种不同信息,我们分别使用颜色直方图,HOG/GIST 描述子和卷积神经网络进行有针对性的提取。
3.1 颜色直方图提取
在我们的方法中,我们使用 RGB 色彩空间来提取交通标识的颜色信息。一张 RGB 图像由三个颜色通道构成。我们首先将输入的交通标识图像拆分为这三个颜色通道,然后分别计算各自的直方图,在这里将每个通道直方图分为 8 个 bar,然后将这三个直方图的 8 个数据拼接起来,最终得到一个长为 24 的向量。
为了提升对颜色的描述能力,我们将每个通道的直方图数据分别相乘,即得到一个 8x8x8 的三维矩阵,称为「全局直方图」,将其展平即得到一个长为 512 的向量。
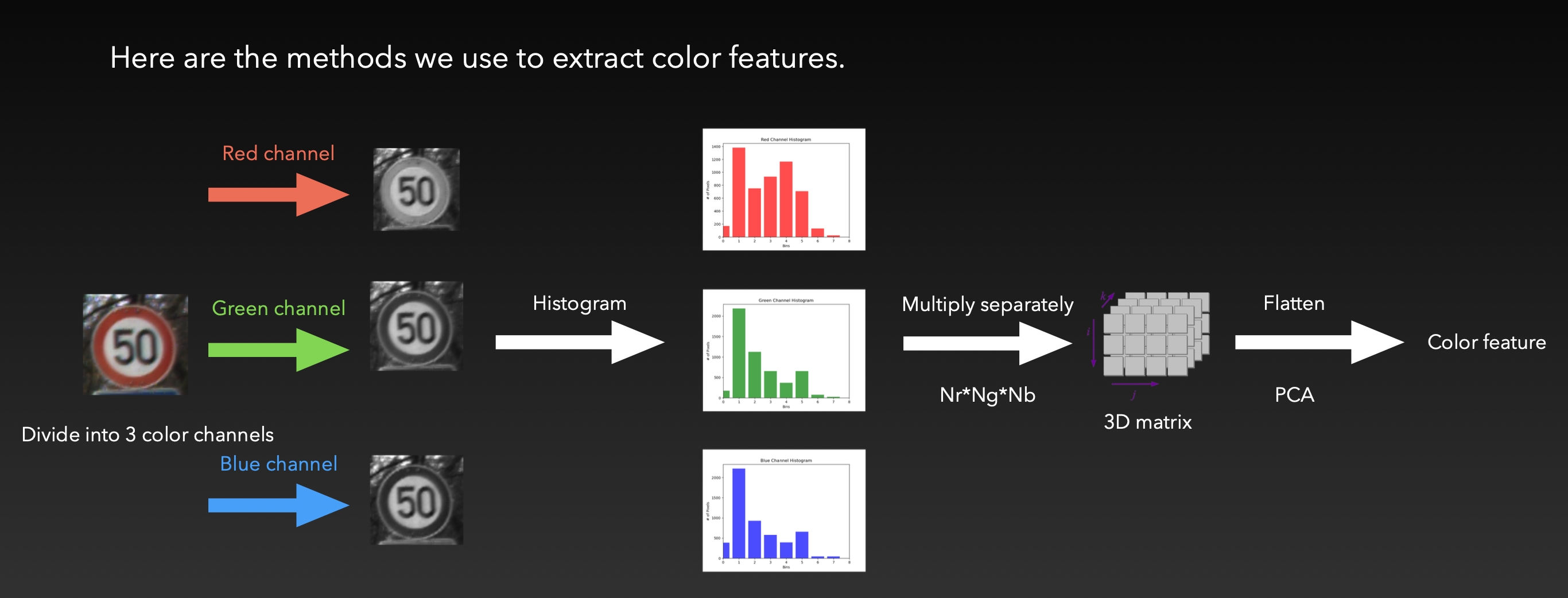
比起之前的拼接得到的向量,全局直方图向量更能体现不同亮度下的颜色信息,更有利于之后的分类。
3.2 形状特征提取
HOG,即方向梯度直方图(Histogram of Oriented Gradients),是一种用于图像特征描述的方法,广泛应用于计算机视觉领域,特别是在目标检测和图像识别任务中。HOG 通过计算图像局部区域的梯度方向分布来捕捉物体的形状和边缘信息。具体而言,HOG 将图像划分为若干小的连接区域,称为“单元格”,然后计算每个单元格内像素点的梯度方向和幅值,并将这些梯度方向进行量化,形成方向梯度直方图。接着,将相邻的多个单元格组合成“块”,并对块内的方向梯度直方图进行归一化处理,以增强对光照变化和对比度变化的鲁棒性。最终,将所有块的特征向量串联起来,形成整幅图像的 HOG 特征描述符。这种方法不仅能够有效地捕捉物体的局部形状信息,还具有较好的抗光照变化能力,使其成为许多视觉识别任务中的重要工具。
在实际应用中,交通标识存在不同的形状,如方形,圆形,三角形等。HOG 尤其擅长提取交通标识的形状,从而为分类提供了依据。
3.3 内外纹理特征提取
GIST 是一种用于图像特征提取的方法,主要应用于场景识别和图像检索任务。GIST 特征描述符通过捕捉图像的整体结构和布局信息,来概括图像的主要内容和场景类型。具体而言,GIST 方法首先将图像划分为若干固定大小的子区域,然后在每个子区域内应用一组 Gabor 滤波器,以提取不同方向和尺度下的纹理特征。Gabor 滤波器是一种线性滤波器,用于捕捉图像中的边缘、线条和纹理信息。通过对每个子区域的 Gabor 滤波响应进行均值和标准差计算,形成该区域的特征向量。接着,将所有子区域的特征向量串联起来,得到整幅图像的 GIST 特征描述符。这种方法能够有效地捕捉图像的全局结构信息和空间布局特征,使其在场景分类和图像检索中表现出色。此外,GIST 特征具有较低的计算复杂度和较小的特征维度,适合大规模图像处理任务。
一般来说,交通标识的外圈强调颜色和形状信息,而内圈部分通常包含符号信息,描述了一定的意义。因此我们将图像切分成内外两部分,分别提取信息。由于经过数据预处理,可以基本保证交通标识的图像信息落在内部区域。我们以 8 像素为宽度,将图像外圈划分为「外部」,剩余部分则分为内部。我们对内外部分别应用了 GIST 描述子,并将两部分拼接到一起得到 GIST 描述向量。
将颜色直方图,HOG 和 GIST 三部分向量拼接在一起,即得到我们的多特征融合提取系统。相比单独使用 HOG 或 GIST 进行提取,我们的方法在分类性能上展现出显著的提升。
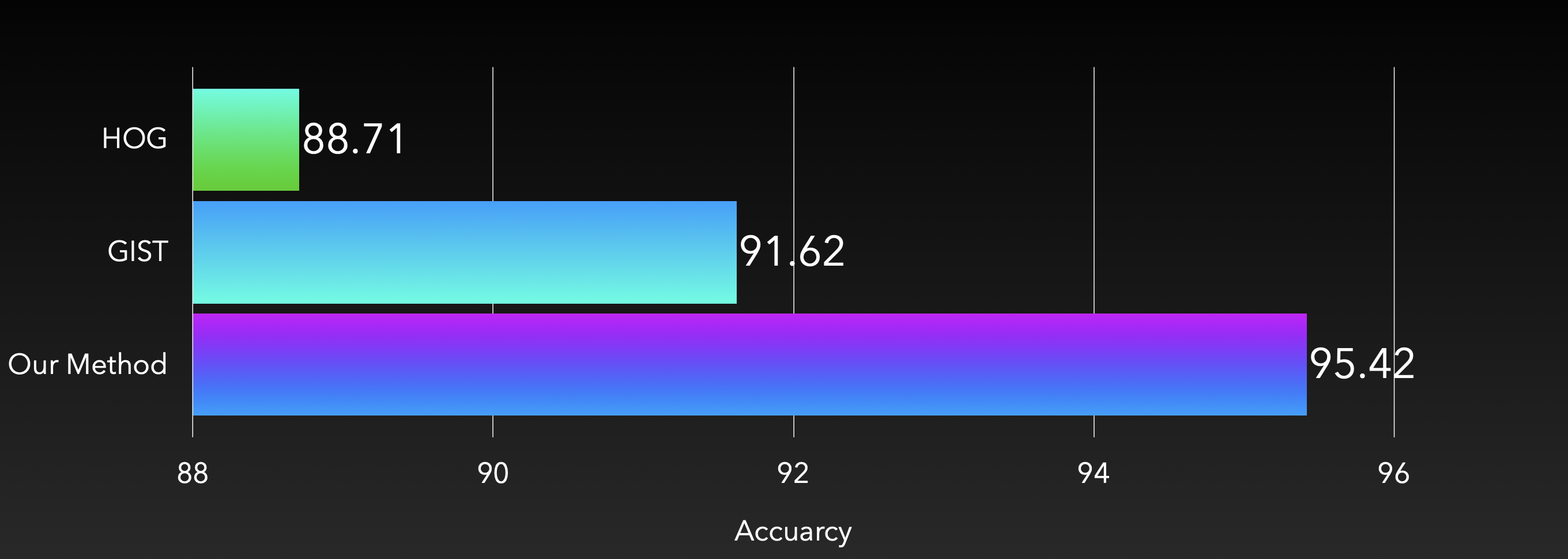
如上图,在德国交通标识分类基准上使用 SVM 分类器,我们的特征提取方案达到了 95.42% 的分类正确率。
3.4 基于 CNN 的符号提取
在检查误分类样本时,我们注意到此方法在提取模糊符号的样本时存在一定的困难。如下图的“50”限速常常被误分类为“80”,说明此方法在提取交通标识中心的符号时,有进一步的提升空间。

通过对两个样本分别进行 HOG 特征提取,可以发现结果也是相似的。
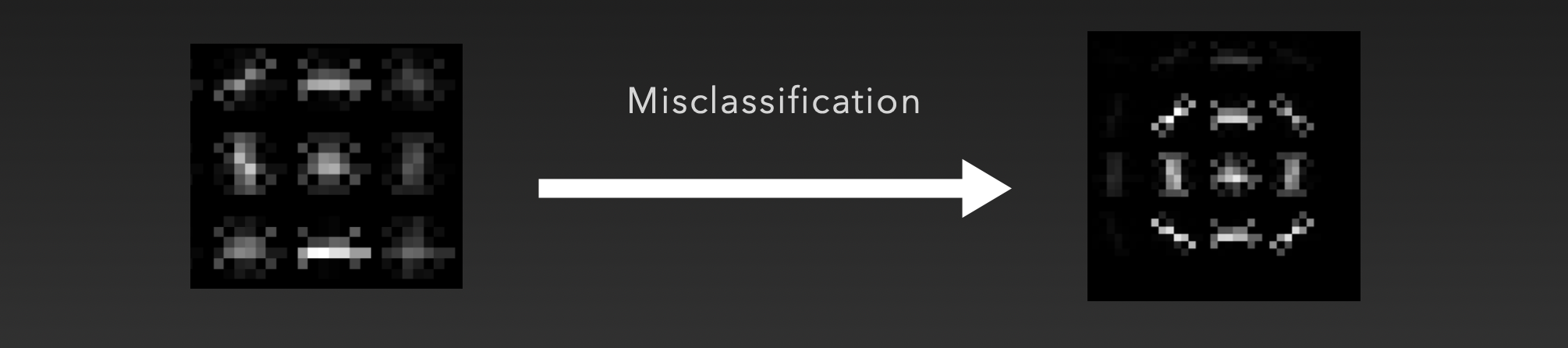
对于这两张交通标识,其颜色和外轮廓形状都完全一致,唯一的不同在于中央的数字,因此我们需要在此方法基础上进行改进,进一步精确地描述交通标识中央的符号信息。
3.4 基于 CNN 的符号信息提取
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,广泛应用于计算机视觉任务,如图像分类、物体检测和图像分割等。CNN通过模拟人类视觉系统的结构和功能,自动提取图像中的特征,实现对图像的高效处理和识别。CNN的基本结构由多个层级组成,主要包括卷积层、池化层和全连接层。
卷积层是CNN的核心层,通过卷积操作提取图像的局部特征。卷积操作使用一组称为卷积核或滤波器的小矩阵,在图像上滑动,并计算滤波器与图像局部区域的点积,生成特征图。这些特征图捕捉了图像的边缘、纹理和其他重要信息。多个卷积层的堆叠使得CNN能够提取越来越高级的特征,从低级的边缘和纹理到高级的形状和对象。
池化层通常在卷积层之后,用于下采样特征图,减少特征图的尺寸和计算复杂度。常见的池化操作包括最大池化和平均池化。最大池化保留池化窗口内的最大值,而平均池化计算窗口内像素值的平均值。池化操作使得CNN具有一定的平移不变性,即对图像的小幅度平移变化不敏感。
全连接层位于CNN的最后阶段,用于将提取到的特征映射到输出空间,完成分类或回归任务。全连接层中的每个神经元与上一层的所有神经元相连,通过加权求和和非线性激活函数,生成最终的输出。
之前的实验结果说明,现有的方法不能很好地感知中心位置的符号信息。为此,我们引入了一个简单的卷积神经网络辅助提取符号信息。具体方式如下,我们提取输入交通标识的中心部分,并基于训练集训练了一个 CNN,其输出为类别的独热编码。其最后一个隐藏层长度为 512,这就是我们认为的「中心符号特征」
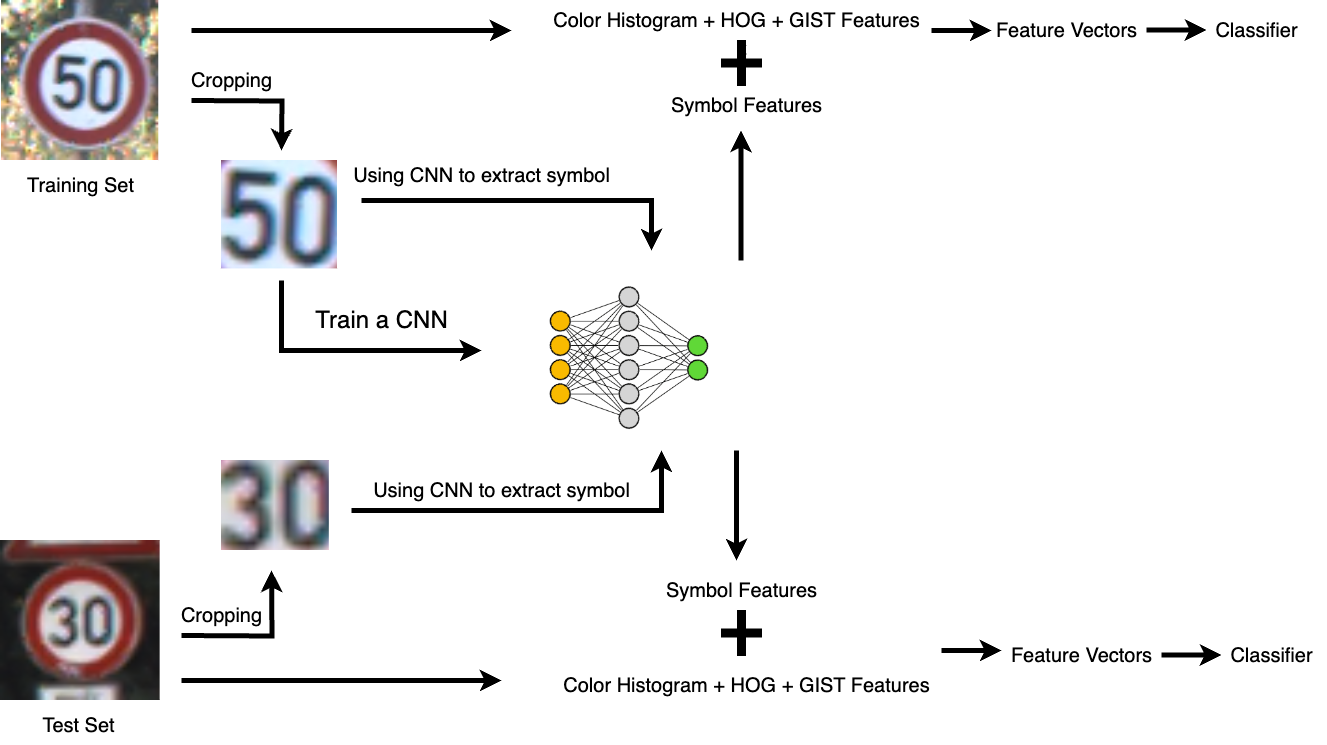
将此 CNN 应用在测试集上,并且将隐藏层的特征信息直接输出,即可作为中心符号特征。将这里的中心符号特征与之前的其他的特征拼接,即可得到最终的多特征融合的特征向量。
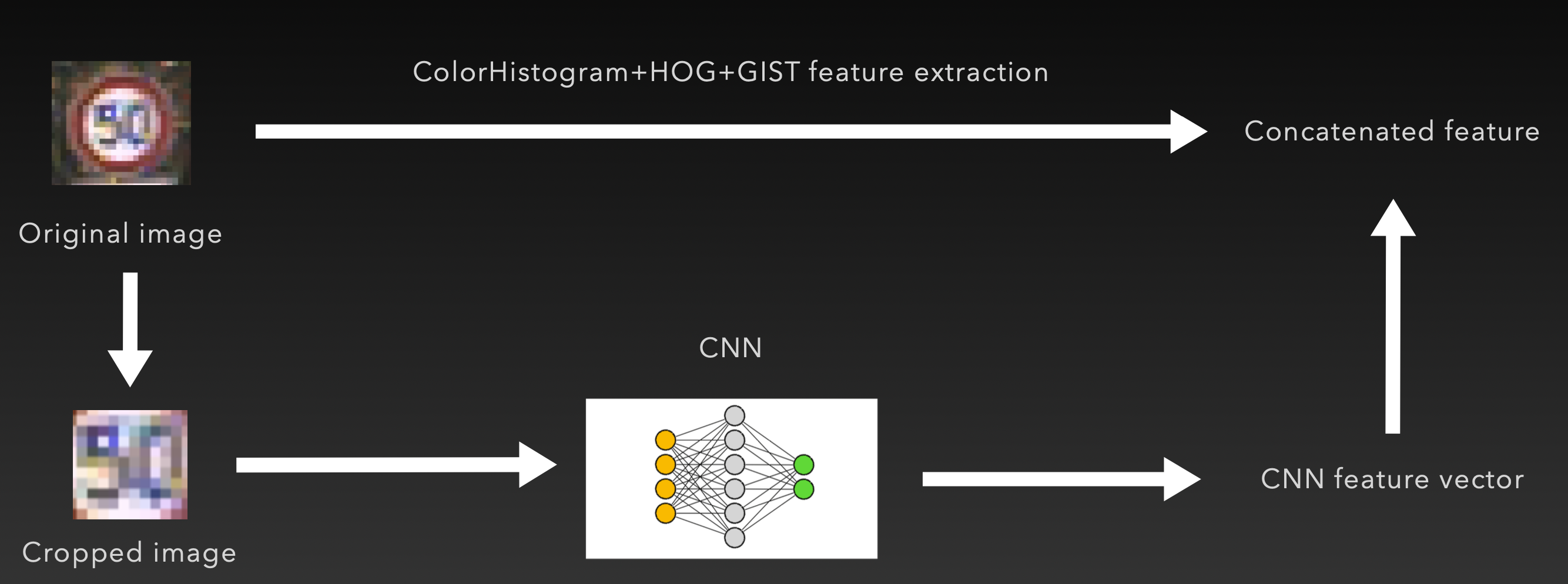
3.5 PCA 降维
PCA,即主成分分析(Principal Component Analysis),是一种常用的数据降维技术,广泛应用于统计学、信号处理和机器学习等领域。PCA通过线性变换将原始高维数据映射到低维空间,尽可能保留数据的主要信息。具体来说,PCA首先对数据进行中心化处理,即减去每个维度的均值,使数据的均值为零。然后,计算数据的协方差矩阵,并求解该矩阵的特征值和特征向量。特征向量代表新的坐标轴方向,特征值则表示这些方向上数据的方差。接着,根据特征值的大小排序,选择前k个特征值对应的特征向量,构成新的低维空间。这些特征向量称为主成分,它们是原始数据中方差最大的方向。最后,将原始数据投影到这些主成分上,得到降维后的数据。PCA不仅能够有效地减少数据的维度,降低计算复杂度,还能够去除噪声,提高数据的可解释性和模型的泛化能力。
由于我们的方法集成了四种不同方面的特征,因此有必要使用 PCA 来进行特征降维,以及对不同方面的特征维度进行权衡。具体来说,我们将颜色直方图、HOG 特征、GIST 特征和 CNN 特征都进行一次 PCA 降维后,再进行拼接。并通过分析误分类样本,判断在颜色、形状、纹理和符号四个方面中误分类的次数,以此作为依据对四个 PCA 方案的维度进行相应的调整。经过实验,我们认为下面的维度数是适合的
- 颜色直方图:32
- HOG 特征:64
- GIST 特征:64
- CNN 特征:256
按照此方案,我们得到的性能如下
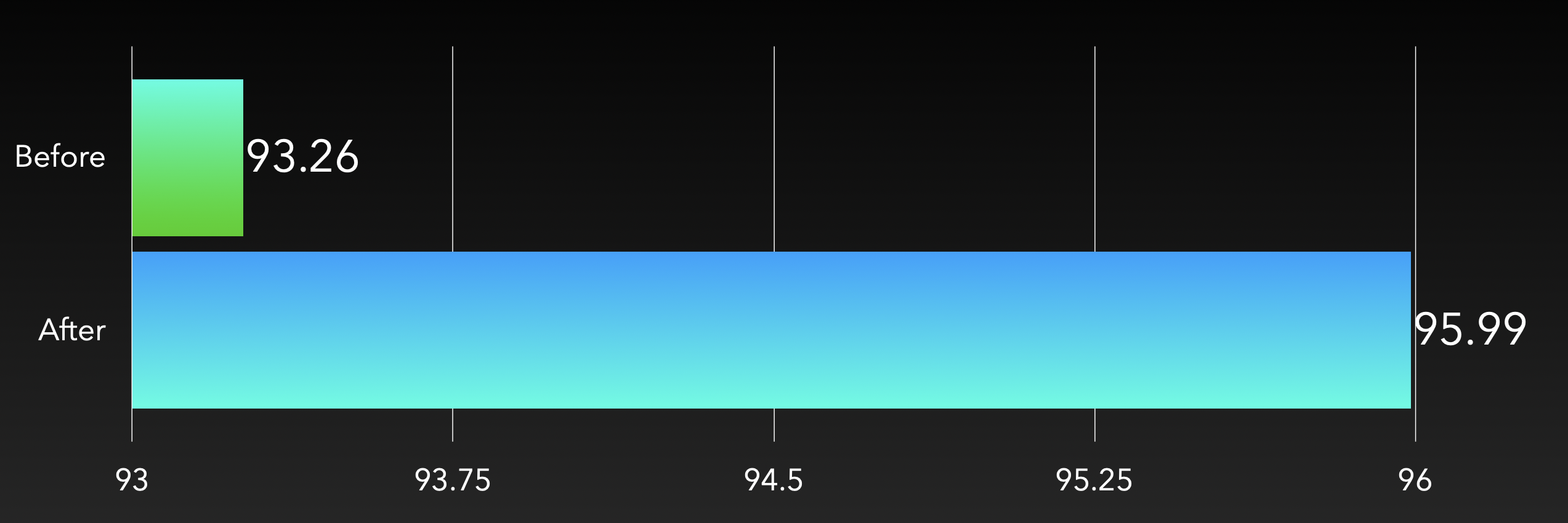
可见,综合了 CNN 和 PCA 技术后,我们的分类正确率有了显著提升。
4. 分类器
在分类器的选择上,我们尝试了 KNN,朴素贝叶斯,MLP 和 SVM 四种主流的分类器。在同样的设置下,其性能如下
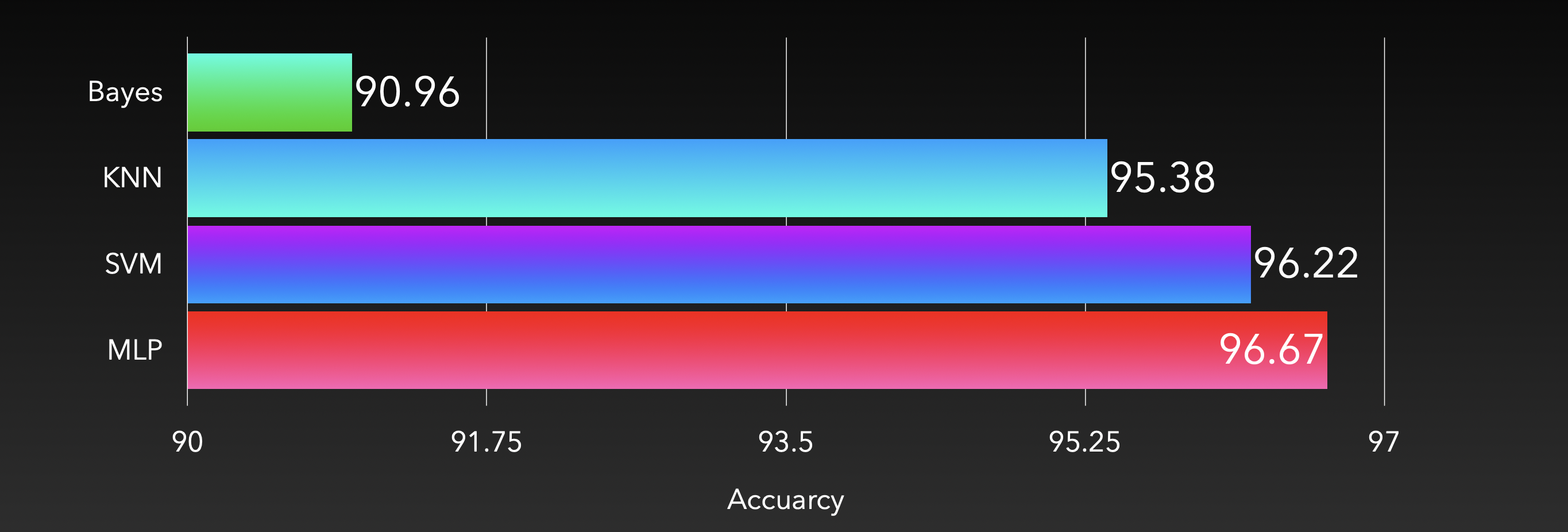
由此可见,朴素贝叶斯分类器表现较差,而另外三种分类器都取得了比较不错的效果。我们认为可能是由于提取出的特征并不满足朴素贝叶斯分类器所要求的条件独立性假设导致的分类效果一般。
5. 集成学习
考虑到 GTSRB 数据集中有大量的复杂光照,运动模糊和噪点,我们认为采用集成学习能够在一定程度上帮助分类器提高预测精度,增强泛化能力和抗噪声能力,提高鲁棒性。我们最终采用 Bagging 作为我们的集成学习策略。
Bagging,全称 Bootstrap Aggregating,是一种集成学习方法,用于提高机器学习模型的稳定性和准确性。Bagging通过创建多个数据集的子集,并在这些子集上训练多个基模型来实现。具体而言,Bagging 首先从原始训练数据集中通过有放回抽样的方法生成多个子集,这些子集彼此之间可能有重复的数据点。然后,在每个子集上训练一个基模型,这些基模型通常是相同类型的,例如决策树。训练完成后,Bagging 将所有基模型的预测结果进行组合,对于分类任务,通过投票机制选择预测次数最多的类别作为最终预测结果;对于回归任务,通过计算所有基模型预测值的平均值来获得最终预测结果。Bagging 的主要优势在于它能够减少模型的方差,从而提高模型的泛化能力,并且在处理高方差模型(如决策树)时效果尤为显著。通过引入多个基模型,Bagging 能够减轻单个模型可能出现的过拟合问题,从而提升整体模型的稳定性和准确性。
在我们的方法中,通过在 SVM 和 MLP 上使用 Bagging 策略,在预测精度上表现出了一定的提升。
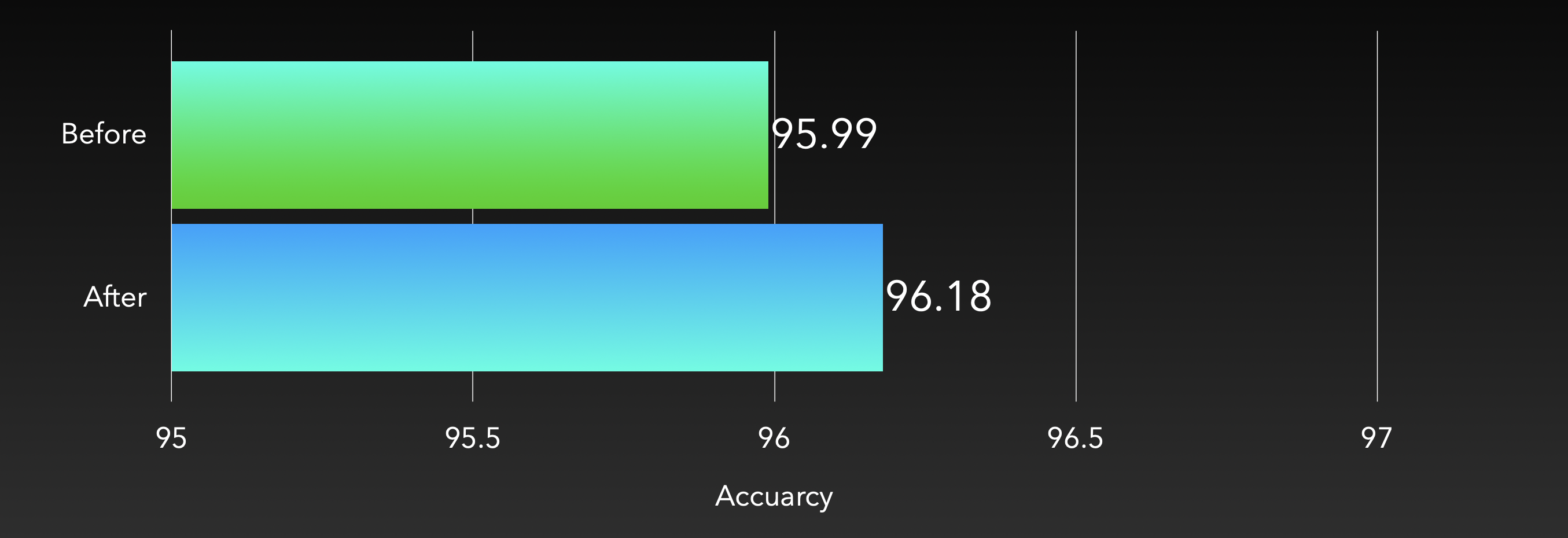
6. 小结
通过综合多特征融合提取以及在 MLP 上应用 Bagging 策略,我们在 GTSRB 数据集上取得了 96.75% 的正确率。相较于传统机器学习方法的分类精度有限,和直接使用 CNN 的高计算复杂度,我们巧妙地以一个简单的 CNN 作为特征提取手段,与其他特征信息融合,使用传统机器学习分类器在计算复杂度和分类正确率上达到了巧妙的平衡。
发表回复