原文链接参见 Unsupervised Adversarial Domain Adaptation for Implicit Discourse Relation Classification,作者:Hsin-Ping Huang和Junyi Jessy Li
「论元」(Argument)在自然语言处理中指具有语义的文本片段,如句子,文章等。论元之间的语义关系称为篇章关系。没有明确关联词的篇章关系称为隐式篇章关系。由于缺乏足够的信息,对隐式篇章关系进行分类是比较困难的。
本文基于 Closing the Gap Domain Adaptation from Explicit to Implicit Discourse Relations,在其基础上作了改进。通过结合对抗差异域自适应和重建映射技术来保护了目标特征的差异性,从而实现了更好的隐式篇章关系分类。
一、模型架构
首先对各概念进行数学符号定义。记输入的论元为 $x$,两个论元对应的篇章关系为 $y$。
对于无监督的域自适应,源域中的样本表示为 $(X_s,Y_s)$,目标域样本表示为 $(X_t)$。在此语境下,源域中的样本表示即为显式篇章关系,目标域则为隐式篇章关系
本文使用 ADDA 作为域自适应的潜在框架。ADDA 首先学习到源域分类过程中的差异表示,然后让目标域模仿源域分布,来学习对应的表示。当目标表示与其源相吻合时,将会执行一次「更新」。这过程类似于 Generative Adversarial Networks 加上了 DANN 的训练过程。
对于源域和目标域,ADDA 学习到了不同的特征编码器,而不是使用同一个编码器,因此直观上来说,一个网络不需要同时处理来自两个域的实例。

综上,模型的架构如下:
- 预训练一个源编码器 $M_s$ 和一个源分类器 $C$
- 对抗适应:通过 $M_S$ 的初始化,训练出一个目标编码器 $M_t$ ,并以对抗的方式训练出判别器 $D$,从而最小化目标和源的表示分布 $M_t$ 和 $M_s$ 两者之间的域差异距离。
- 最后,经过训练的目标特征空间能够匹配源的,此时源分类器 $C$ 就可以直接被用于目标域。
1. 基础编码器和分类器
首先在源域上做文章。在本文的语境下,就是先从显式数据中学得足够多的知识。这个过程可以通过预训练一个源编码器 $M_s$ 和一个源分类器 $C$ 来实现。通过这一有监督学习过程,我们应该能够预测显式篇章关系。编码器将关系论元编码成潜在表示的形式,然后将这些表示输入到分类器 $C$ 来对篇章关系进行预测。
1.1 编码器
编码器借助双向 LSTM 来为每个论元生成表示,然后两个论元的表示被拼接到一起,来形成最终的表示,过程如图
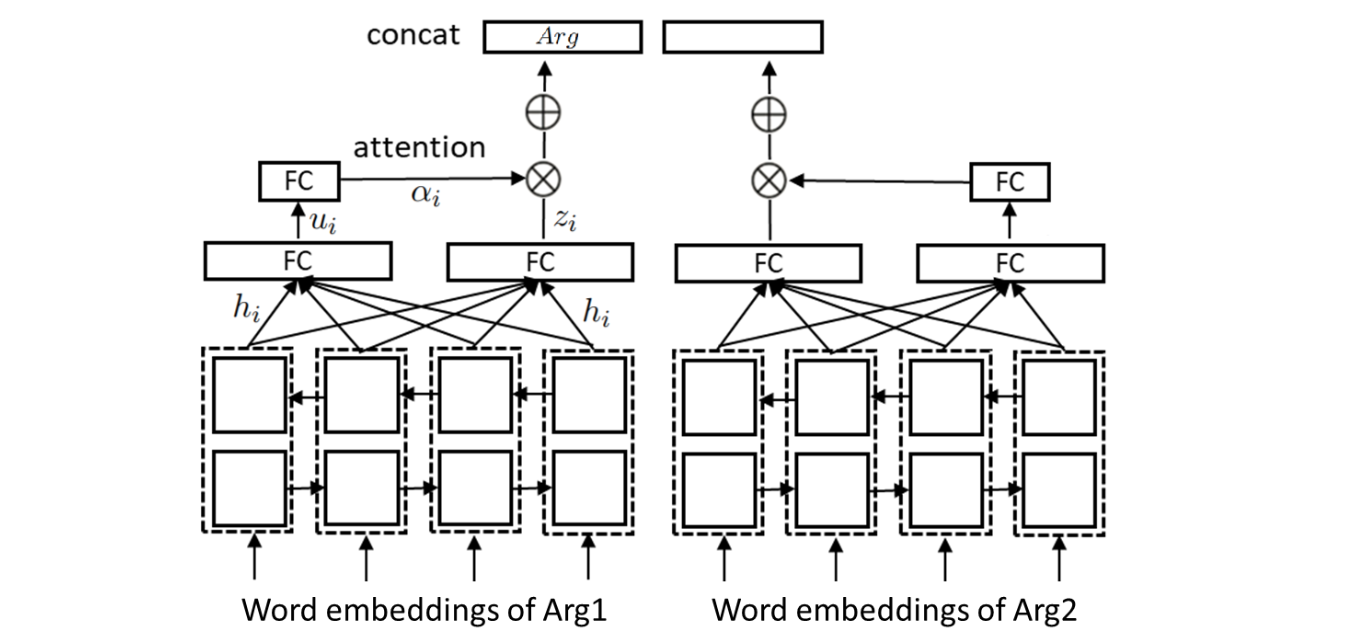
编码器将论元中的每个单词编码为对应的词向量形式后输入双向 LSTM,将隐藏状态拼接到一起,即 $h_i=[\overrightarrow{h}_i,\overleftarrow{h}_i]$,然后通过一个全连接层 $W_c$,从而得到隐藏表示 $z_i$,即
$$z_i=W_ch_i+b_c$$
然后借助注意力机制,生成一组权重分布。这些权重指示了论元对于每个单词的关注程度或重要性,即
$$u_i=\tanh (W_wh_i+b_w)$$
$$\alpha_i=\frac{\exp(u_i^Tu_w)}{\sum_i\exp (u_i^Tu_W)}$$
最终,论元 $Arg$ 被编码器编码为
$$Arg=\sum_i\alpha_iz_i$$
在上述过程中,$W_c,b_c,W_w,b_w,u_w$ 为模型的参数。
1.2 分类器
分类器就是一个在编码器上的全连接层,然后以 softmax 分类层作为输出。源编码器 $M_s$ 和分类器 $C$ 在训练时使用监督损失如下
$$\min_{M_s,C}\mathcal{L}{cls}(X_s,Y_s)=E{(x_s,y_s)}-\sum_kl[k=y_s]\log C(M_s(x_s))$$
2. 无监督对抗域自适应
接下来需要训练一个能够为目标数据生成特征的目标编码器 $M_t$,在训练过程中是没有标签 $Y_t$ 的,因此是一个无监督学习。这里的目标编码器 $M_t$ 采用的架构与上文的源编码器 $M_s$ 的架构是相同的,但 $M_t$ 是用 $M_s$ 初始化得到的。
为了让新的目标编码器「足够像」源编码器,可以借鉴 GAN 的思路,通过训练一个「域判别器」$D$ 来实现的。域判别器需要尝试判断一个特征是来自于源域还是目标域,而目标编码器 $M_t$ 生成的特征需要尽可能与源编码器相似,从而欺骗域判别器。在此过程,目标编码器就会越来越像源编码器
域判别器根据如下的监督损失进行训练
$$\min_{D}\mathcal{L}_{adv_D}(X_s,X_t,M_s,M_t)=-E_{x_s}[\log D(M_s(x_s))]-E_{x_t}[\log (1-D(M_t(x_t))]$$
$D$ 由编码器上的两个全连接层以及一个 softmax 分类层构成。目标编码器 $M_t$ 则根据标准的 GAN 损失来训练
$$\min_{M_t}\mathcal{L}_{adv_M}(X_s,X_t,D)=-E_{x_t}[\log D(M_t(x_t))]$$
2.1 谱归一化
为了稳定判别器的训练,需要使用谱归一化。谱归一化不需要额外调整其他超参数,也不需要太多计算代价。
2.2 标签平滑
为了使用源分类器对目标表示进行分类,目标编码器需要模仿源编码器来输出表示。由于在此训练阶段没有使用任何监督损失,目标编码器可能无法生成一些原本一些有助于分类的差异化特征。
为了解决此问题,作者加入了一个「重建损失」(Reconstruction Loss)来确保目标编码器在对抗适应其特征时,能够保留其差异化性。
由于目标编码器是用源编码器初始化的,因此在域自适应之前,对于一个目标实例 $x_t$ 的初始表示实际上就是 $M_s(x_t)$。在训练后,$M_t(x_t)$ 适应了源域,并且与源域编码器 $M_s(x_t)$ 不相似,重建损失的作用是鼓励目标编码器生成的特征能够被重建回源域编码器 $M_s(x_t)$ 的特征。
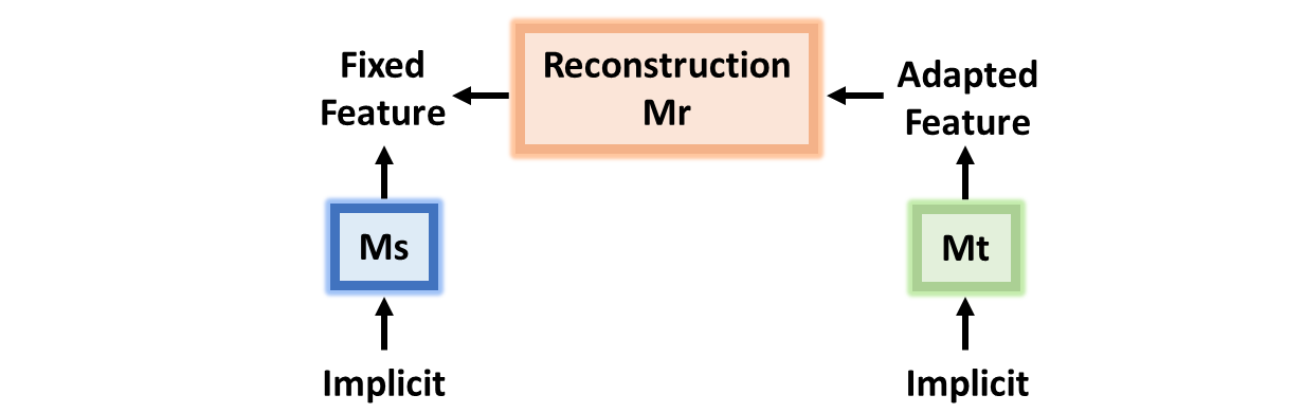
对于目标样本 $x_t$,我们学习到一个「重建映射」(Reconstruction Mapping)$M_r$,将 $M_t(x_t)$ 映射到 $M_s(x_t)$,即
$$x_t\to M_t(x_t)\to M_r(M_t(x_t))\approx M_s(x_t)$$
其中目标编码器 $M_t$ 和重建映射 $M_r$ 通过重建损失来共同训练和优化
$$\min_{M_t,M_r}\mathcal{L}_{recon}(X_t,M_s)=E_{x_t}[||M_r(M_t(x_t))-M_s(x_t)||_2^2]$$
其中 $M_r$ 由编码器上的三个全连接层组成。
2.3 无监督目标函数
对于无监督的域自适应,完整的损失函数为
$$\begin{aligned}
\mathcal{L}^{unsup}(X_s,Y_s,X_t,M_s,M_t,D)&=\min_{M_s,C}\mathcal{L}_{cls}(X_s,Y_s)\&+\min_D\mathcal{adv_{D}}(X_s,X_t,M_s,M_t)\&+\min_{M_t}\mathcal{L}_{adv_M}(X_s,X_t,D)\&+\min_{M_t,M_r}\mathcal{L}_{recon}(X_t,M_s)
\end{aligned}$$
3. 训练
训练的过程可以分为三部分:预训练,对抗适应以及测试。
- 预训练期间,训练出源编码器 $M_s$ 和分类器 $C$
- 对抗适应期间,通过交替训练判别器 $D$ ,目标编码器 $M_t$,以及重建映射 $M_r$
- 测试期间,将目标编码器和分类器进行测试。
二、实验过程
1. 设置
在实验数据方面,作者使用 PDTB 作为实验数据。其中训练集隐式关系为 21-22 小节,显式关系来自 02-20 和 23-24 小节。显式和隐式的验证集来自 00-01 小节,数据分布情况如下
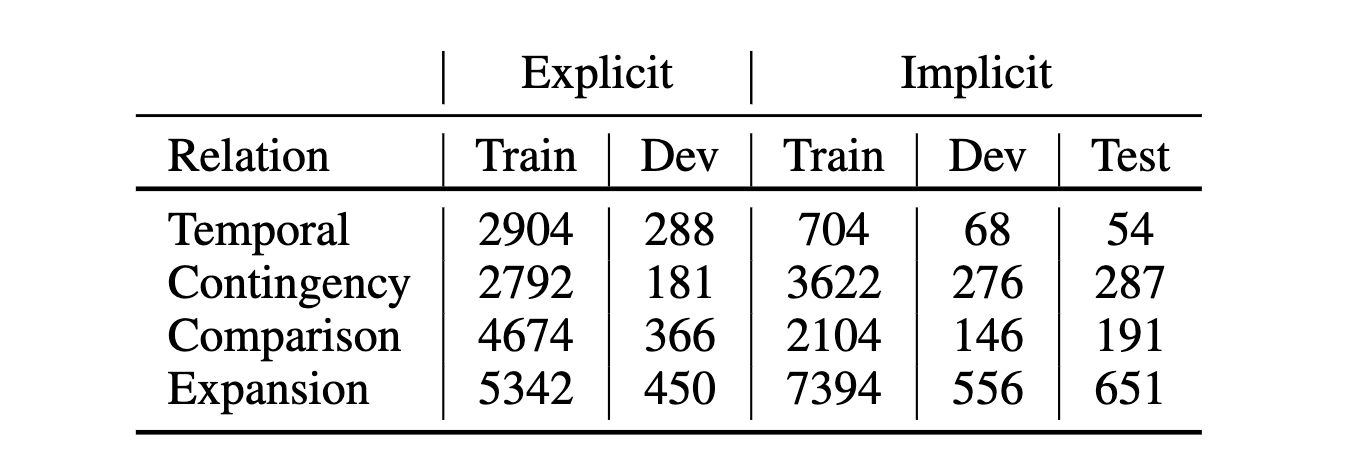
训练时,如果[[macro F1]]不在改善,则早停。在预训练阶段,大概在 20 个 epochs 就需要早停,而在对抗适应阶段,早停大概发生在 5 个 epochs 之后。
在此模型中,超参数主要有分类器 $C$,判别器 $D$ 和重建映射 $M_r$ 的全连接层数。这些超参数都是通过在验证集上的表现进行设置的。
2. 设置
作者的实验采用了三种设置
- 隐式到隐式:使用基础编码器和分类器实现的有监督的隐式篇章关系分类器,使用标准交叉熵损失进行优化,并且在训练和验证都只是用隐式数据。
- 隐式到显式:使用显式训练集和隐式验证集实现的隐式篇章关系分类器,使用标准交叉熵损失进行优化。此设置作为没有域自适应的参照。
- 域自适应:使用显式数据集和没有标签的隐式数据集训练得到的带有域自适应的模型。
此外,对于训练时采用的三种不同的 trick:谱归一化、标签平滑以及重建损失,作者在加入与不加入的情况又做了多次试验。
为了参照,作者也使用 DANN 训练了一个无监督域自适应系统。
3. 结果
为了评价模型,作者训练了 4 种分类器并且计算了每种类别以及全局的F1 分数,如下
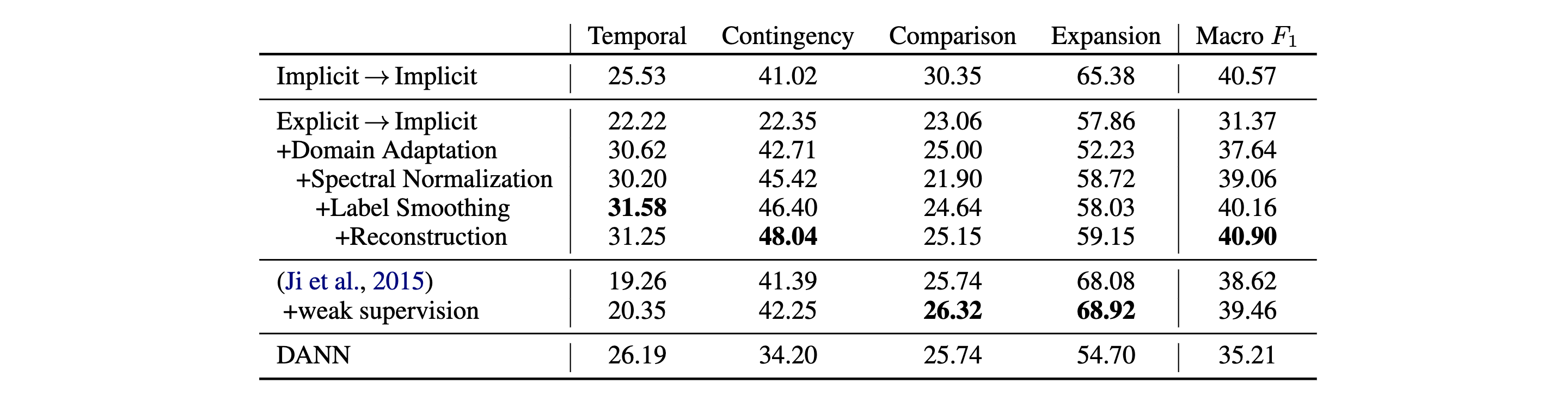
可见,此论文中的模型实现了最佳的平均 F1 分数,比起一般的「显式到隐式」,有高达 $9.53%$ 的性能提升。其中最大的提升出现在「Temporal」和「Contingency」。
值得注意的是,在使用了域自适应后,「Expansion」的表现略有下降。作者怀疑这是因为 Expansion 的分布不同导致的。通过谱归一化,性能就有所改善了。
- 谱归一化改善了「Contingency」和「Expansion」的性能,而「Comparison」却下降了。
- 标签平滑改善了除了「Expansion」之外的所有关系的性能。
- 重建损失改善了除了「Temporal」之外的所有关系的性能。
总的来说,同时应用这三种 trick 可以得到最好的性能
发表回复